Pandemic Crowdsourcing with Wikidata
During the COVID Pandemic I saw this tweet from an old colleague at the National Library of Wales.
Our volunteer team have just started an exciting new project to tag the location of things depicted in our #openaccess images using the #IIIF. The data will be saved to #Wikidata - https://t.co/TZIcdr3Llk pic.twitter.com/gIbapKxh1h
— Jason Evans (@WIKI_NLW) January 28, 2020
This is another great idea for allowing volunteer engagement without having to setup a large amount of infrastructure. Jason made use of a tool called Wikidata Image Positions which allows users to tag different regions of an image with an entity from Wikidata. This could be generic tags like farm, windmill, cattle or horse but can also be specific tags like Aberystwyth or the particular Church depicted in a painting.
Jason was able to manage the project using a spreadsheet which contains links into the tool like this one:
https://wd-image-positions.toolforge.org/item/Q21614047
which opens up one of the images ready for volunteers to start annotating. All the volunteers needs is a Wikipedia login.
The Wikidata Image Positions tool also creates a IIIF Manifest which can be used in a normal IIIF Viewer. See this example manifest and the Manifest in Mirador 3.
For this project the images need to be on Wikimedia so will work with any type of Image. If you already have IIIF Images then these would also need to be uploaded to Wikimedia but through the use of a IIIF Manifest property it should be possible to map the annotations back to the original IIIF images.
The Madoc Crowdsourcing System
Extending this project further the National Library of Wales also embedded this feature into a more classic crowdsourcing application called Madoc. This allows a more controlled volunteer process and links the Wikidata entries to the original IIIF Image.
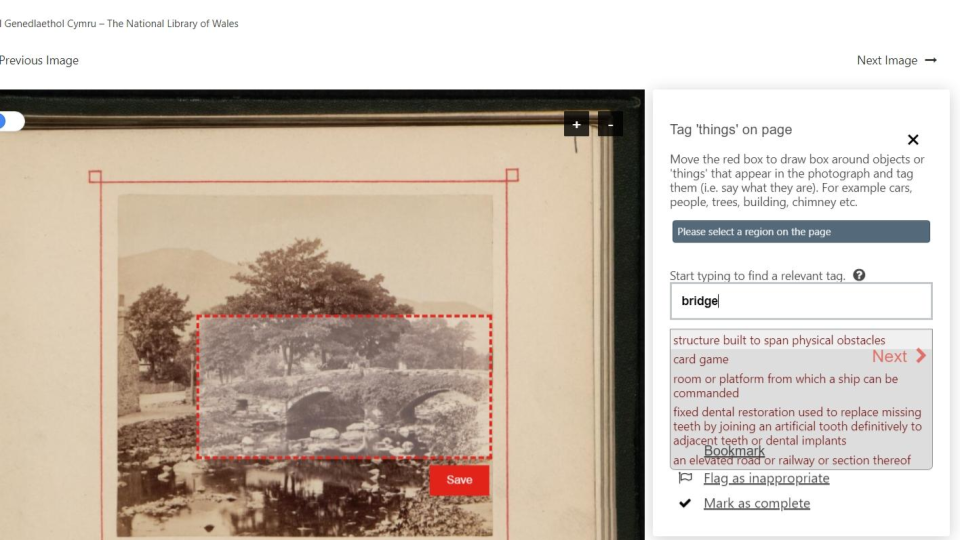
The National Library of Wales have also used this Crowdsourcing system to get volunteers to transcribe other material including a 15,000 pages of a collection of WW1 Welsh Tribunal Records. These are the applications made by people in Ceredigion, a county in Wales for exemption to national service. You can see below that Madoc can be configured to customise the data captured.
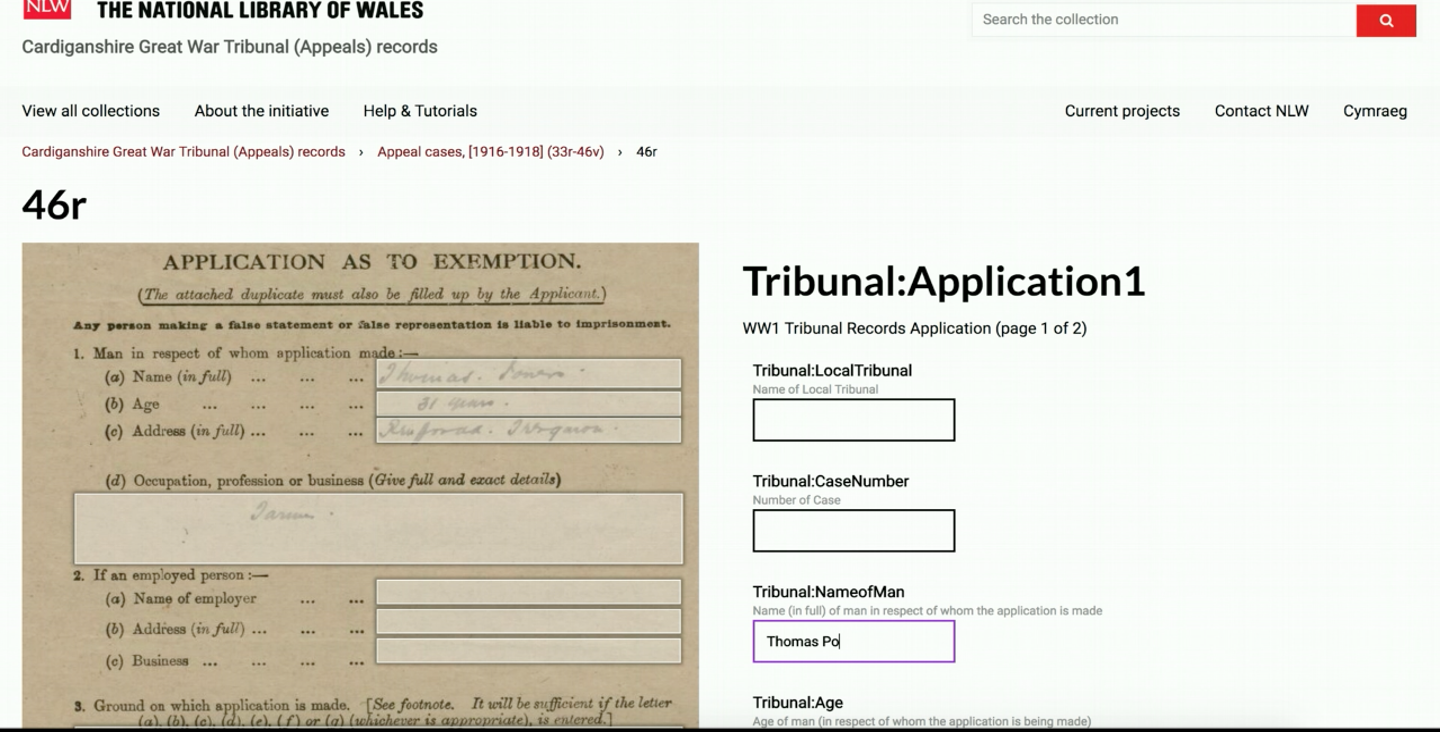
The volunteers completed the transcription in about 6 months and the data is made available in a similar way to the Book of Remembrance. The annotations are searchable using the Universal Viewer on the project webpage:
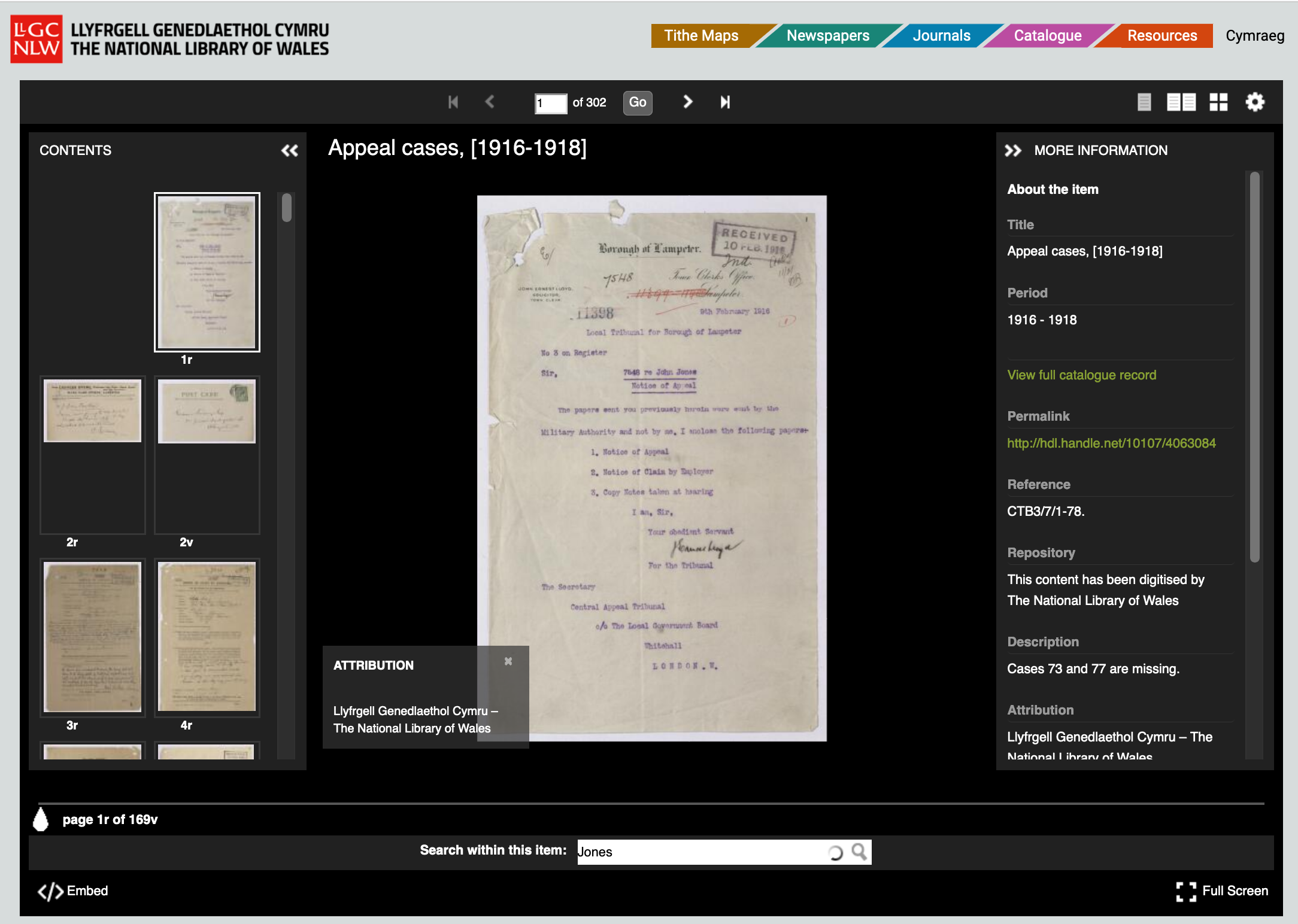
The NLW have also made the source annotations available for research:
https://github.com/NLW-paulm/Welsh-Tribunal-annotations
and similarly it is possible to create various visualisations of the data including looking at the reasons for exemption:
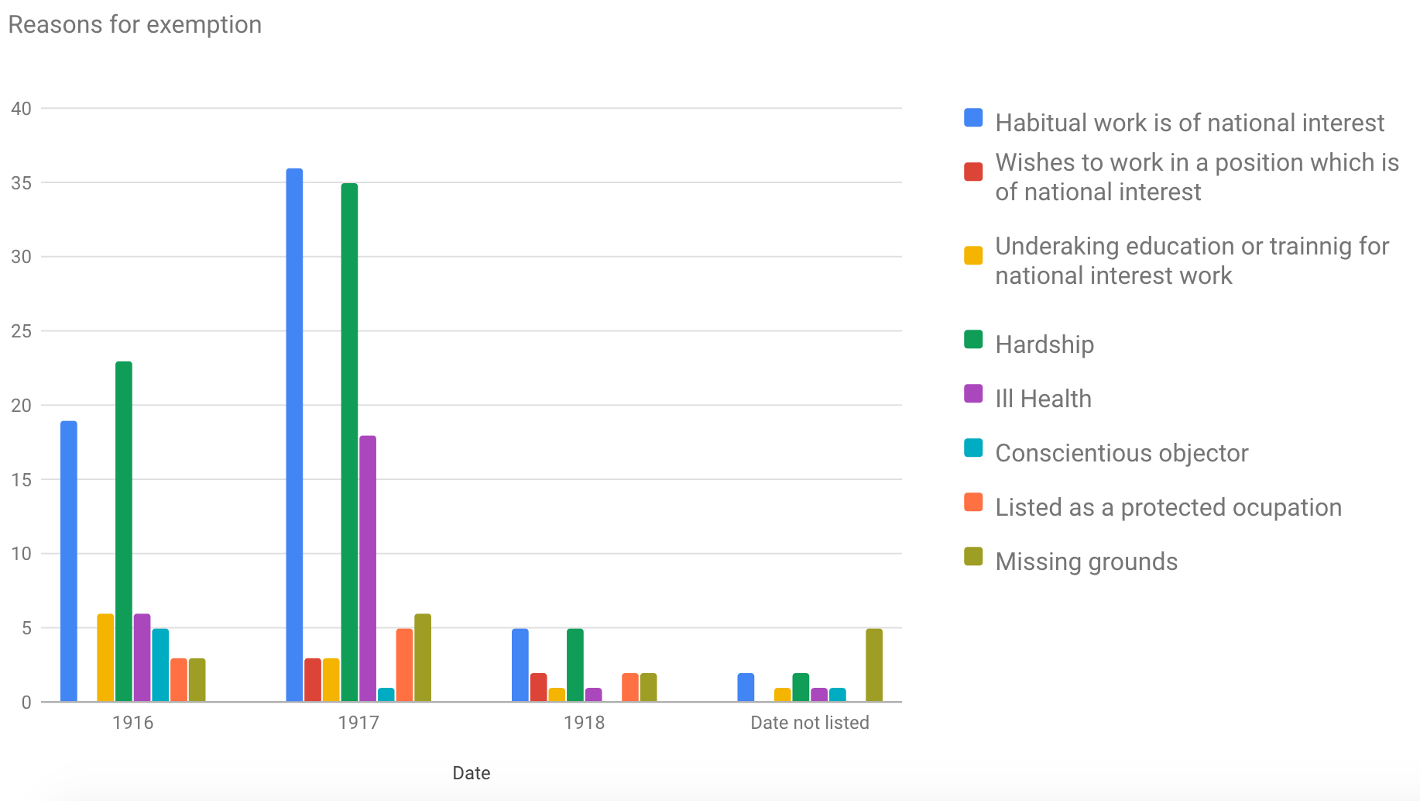
A full write up of this investigation is available here.